Concurrent Map in Go vs Java: Yet Another Meaningless Benchmark

A
Core database engineer at QuestDB. Distributed systems gazer. Node.js contributor. Occasional tech blogger and speaker.
Search for a command to run...
Core database engineer at QuestDB. Distributed systems gazer. Node.js contributor. Occasional tech blogger and speaker.
Very interesting. What I would really like to know is how this scales to hundreds/thousands of threads. I suspect that with the current implementation Go will beat Java due to the limitations of system threads and with Loom we'll see Java turn that around.
Read operations will scale only with increased CPU core count. As for writes, they might scale better in Go with increased number of goroutines as long as the hash table bucket count is large enough. That's because of cheaper context switches in green threads vs OS threads. Project Loom may indeed change that.
This small post continues the previous post dedicated to multithreaded query execution in databases with column-oriented storage format. This time we'll consider queries like the following: SELECT SearchPhrase FROM hits WHERE SearchPhrase IS NOT NULL...

mmap is a controversial topic among the database community. The common belief is that it's no good for a database, but in my experience, it does a decent job for an analytical database, when you want to scan columns stored in a column-oriented format...

Last time we discussed k-word CAS algorithm and came to the conclusion that seqlock-based atomic snapshots may be used as an alternative in situations when your writes are infrequent and single-writer limitation is acceptable, but you want the reader...

A few months ago I went through Efficient Multi-word Compare and Swap paper, so here are a few thoughts on the algorithm. Long story short, I have mixed feelings about this k-word CAS algorithm. It focuses on nice properties of the CAS operation, suc...

Several times I've heard opinions that many mass-market SSDs and HDDs don't provide sufficient durability guarantees and Linux can do nothing with that. Namely, after an fsync() call recently modified data can still sit in the drive's volatile write ...

Today we're comparing Java's j.u.c.ConcurrentHashMap and Go's xsync.MapOf in a totally non-scientific, unfair benchmark. While most of such language performance comparisons are generally useless and harmful, the purpose of this exercise is a comparison of the algorithms behind both data structures. I'm driven by curiosity here, so don't take this post seriously. The results may be completely different on another HW and in different scenarios, so don't forget that any benchmark has to be taken with a grain of salt.
On the one hand we have ConcurrentHashMap, also known as CHM. It's a brilliant concurrent hash table: no writes to shared memory in read-only operations, hybrid linked list / tree used for buckets depending on the number of stored nodes, volatile value fields in nodes allowing to update the value without having to allocate a new node, a striped counter for the current size, and so on. CHM has been improved across many versions of Java, for many years, so reaching its level of performance isn't an easy task.
On the other hand, MapOf borrows ideas from multiple sources: buckets are organized in unrolled linked lists of cache line size thanks to Cache-Line Hash Table (CLHT), hash codes stored in the buckets to avoid extra hash function calls and pointer chasing, immutable entries to avoid extra synchronization on reads and also reduce GC pressure, also a striped counter for the current size.
Both maps have a bunch of handy atomic operations available to the developer. But enough of this boring stuff, let's do the benchmarking.
Our test stand is nothing more, but a laptop machine with an i7-1185G7 CPU (8 HT cores) and Ubuntu 22.04 running 64-bit builds of Go 1.19.3 and OpenJDK 17.0.4.
The CHM benchmark can be found here, while the Go benchmark is in the xsync repo.
The benchmarks start with a pre-warmed map holding 1,000 64-bit integer key-value pairs. The "99% reads" scenario assumes that each thread spends 99% of its calls on get (Load) operations and 0.5% on both put (Store) and remove (Delete) operations. Each operation is called for a randomly selected key, so there are no hot spots. The "75% reads" scenario is more write-heavy as write operations get 12.5% of total number of operations each.
The benchmarks were run with different number of threads/cores to be used, staring with 1 core and ending with all 8 available cores. That's to see how well both maps scale on multi-core machines. Finally, the below results are based on average values collected after 10 runs of each benchmark.
Let's start with the write-heavy scenario. CHM has an advantage here since it allows updating values in-place, so it might show better results.
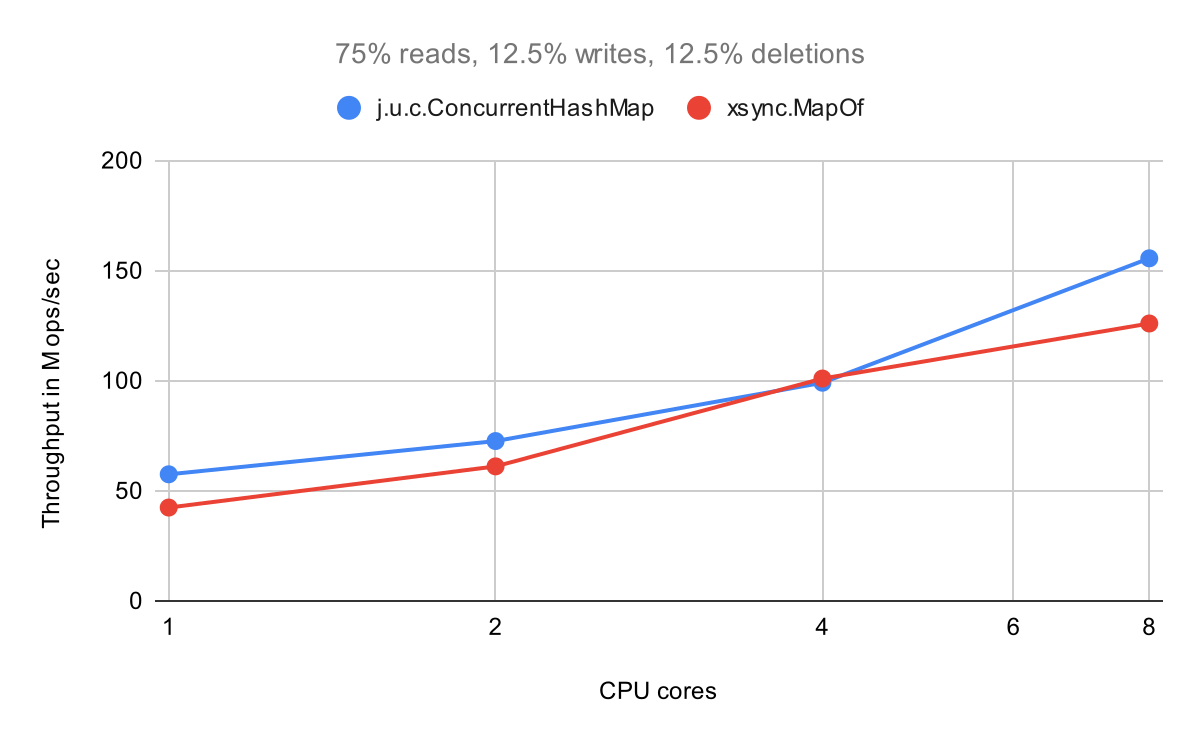
As expected, CHM is slightly better on all core counts except for 4 cores. Both maps scale well enough.
Let's see results for the read-heavy scenario which might be more common in many real world applications.
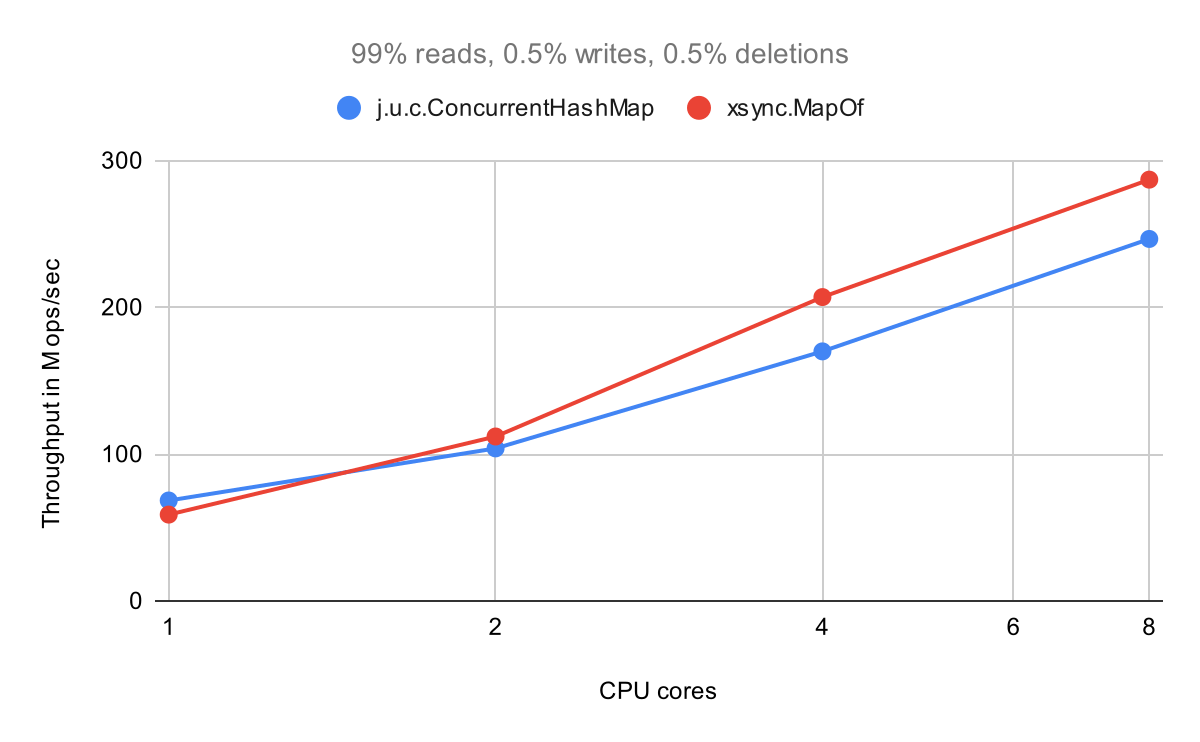
Again, both maps scale well with a slight advantage of MapOf. I'm pretty happy with the results. There are certainly rough edges, but MapOf has proven its worthiness.
Have fun coding and see you next time.