So long, sync.Map

Core database engineer at QuestDB. Distributed systems gazer. Node.js contributor. Occasional tech blogger and speaker.
While the title is certainly a clickbait, I definitely don't see any strong reason to keep dealing with sync.Map if you're a Go generics user. Instead, you should consider xsync.MapOf:
type point struct {
x int
y int
}
// create a MapOf for with keys and values of point type
m := NewTypedMapOf[point, point](func(p point) uint64 {
// hash function to be used by the map
return uint64(31*p.x + p.y)
})
// load the existing value or compute it lazily, if it's absent
v, loaded := m.LoadOrCompute(point{42, 42}, func() int {
return point{0, 0}
})
The above wasn't possible until xsync v1.5.0. That's because the generic version of the concurrent map available in the library supported only string keys. But now you can use any comparable type as a key, so xsync.MapOf became a real, more scalable alternative to the good old sync.Map. Today we're going to discuss the recent changes in the data structure that allowed using arbitrary key types and also do some (as always, non-scientific) microbenchmarking.
The challenges
The original intent behind xsync library was to provide faster alternatives for the built-in concurrent data structures available in the Golang standard library. Most of the alternatives, like RBMutex or MPMCQueue, aren't suitable for general purpose, i.e. they're tailored for niche use cases.
But xsync.Map is different as it was aimed to replace sync.Map in the same scenarios and beyond. It's based on a (noticeably) modified version of Cache-Line Hash Table (CLHT). Read-only operations, such as Load or Range, are obstruction-free while write operations and rehashing use fine-grained locking (lock sharding). Refer to this blog post to learn more on the algorithm. The only significant limitation was in keys limited to the string type.
The original version of the map was non-generic, so you had to deal with unpleasant interface{} rituals in your code. When Go got a stable version of generics, Viacheslav Poturaev contributed a generics-friendly version of the map, xsync.MapOf. This was a nice step forward, but it still supported string keys only.
A few month ago, the library repo received a pull request from Rob Mason. The goal was to allow arbitrary comparable types for keys while maintaining backwards compatibility. Since Golang doesn't expose the built-in hash functions except for what's in the hash/maphash package, the hash function has to be provided by the user which isn't a big deal. The only problem was the layout of the data structure.
Each bucket in the underlying hash table had the following structure:
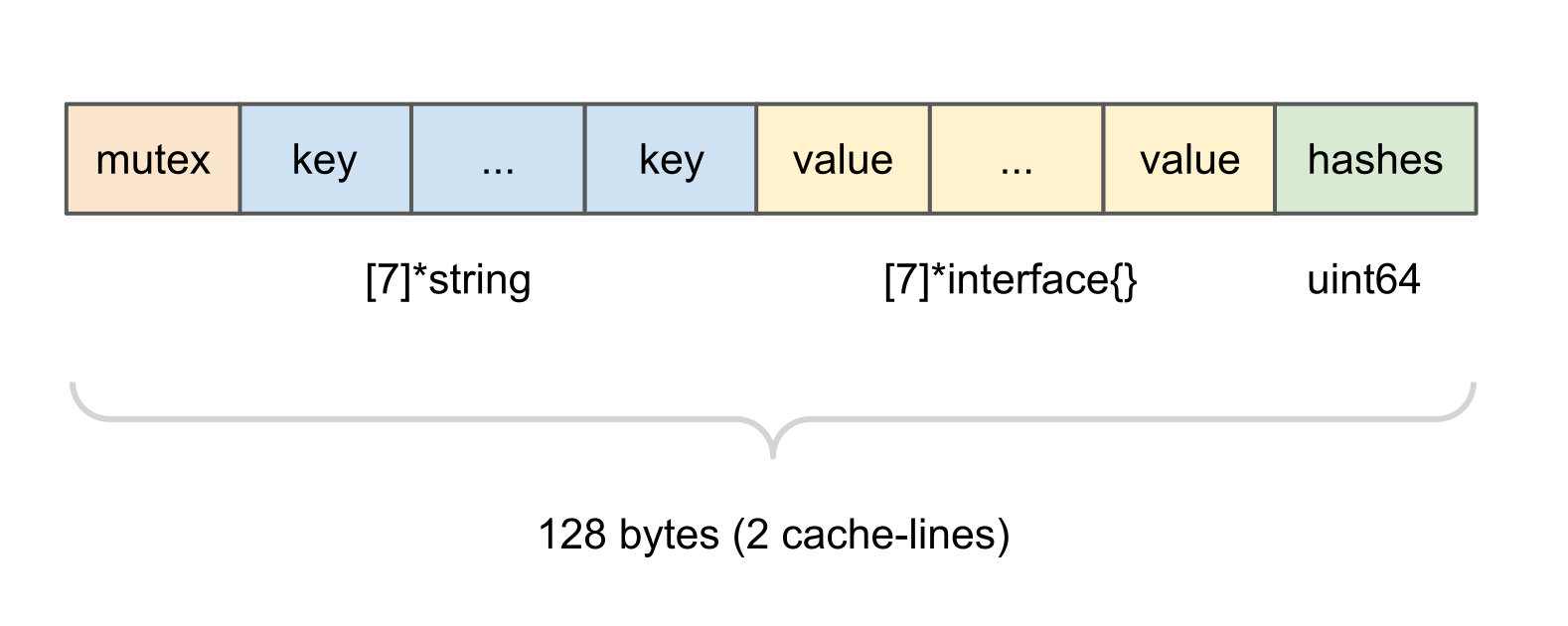
Here we have 128 bytes (two cache-lines on most modern CPUs) holding a sync.Mutex, 7 key/value pairs, and a uint64 with cached hash codes for the keys present in the bucket. The mutex is being used while writing to the bucket. The key/values pairs hold pointers to the map entries. Finally, the hash code cache holds one most significant byte per each key’s hash code.
So, each bucket was able to hold up to 7 key/value pairs and, in case if the bucket was fully on an insert, a rehashing would have to be made. Such design is sufficient if you have a high quality hash function, such as the built-in one for strings. But if the function is user-provided chances of having 7+ perfect hash code collisions in the same map increase dramatically.
To fix that, mutex and hashes fields were merged into a single uint64-based data structure with the following layout:
| key 0's top hash | ... | key 7's top hash | bitmap for keys |
| 1 byte | ... | 1 byte | 1 byte |
Here, we have 8 most significant bits (MSBs) of the hash code for each key stored in the bucket. They're used to avoid many expensive hash code computations on each look up. Before calculating the hash code for a key/value pair, we compare the MSBs with the MSBs of the hash code of the user-provided key and, if they don't match, we move on to the next pair in the bucket. Next, the least significant bit in the "bitmap for keys" byte is used to implement a mutex (a TTAS spinlock, to be more precise).
Merging the mutex and the hash code MSBs together saved gorgeous 8 bytes of memory in each bucket. The saved bytes hold pointers to the next bucket in the chain, so as in the very first xsync version, hash table buckets are now organized in unrolled linked lists. Hence, in face of perfect hash code collisions, the linked list trivially growths until the map load factor is met.
Needless to say that once all of the above was done, supporting any comparable key type finally became possible.
At this point you may be asking yourself if it's using a non-standard map is worth it. Let's see.
The promised benchmarks
The following results were obtained on i7-1185G7, Ubuntu 22.04 x86-64 and Go 1.19.2. The benchmark source code itself can be found in the xsync repo.
We start with a benchmark that uses a pre-warmed map with 1,000 key/value pairs. The keys are strings while the values are ints. The benchmark uses all 8 goroutines to load all 8 HT cores available on the machine. Each goroutine selects a key randomly and executes either Load, Store or Delete operation on it.
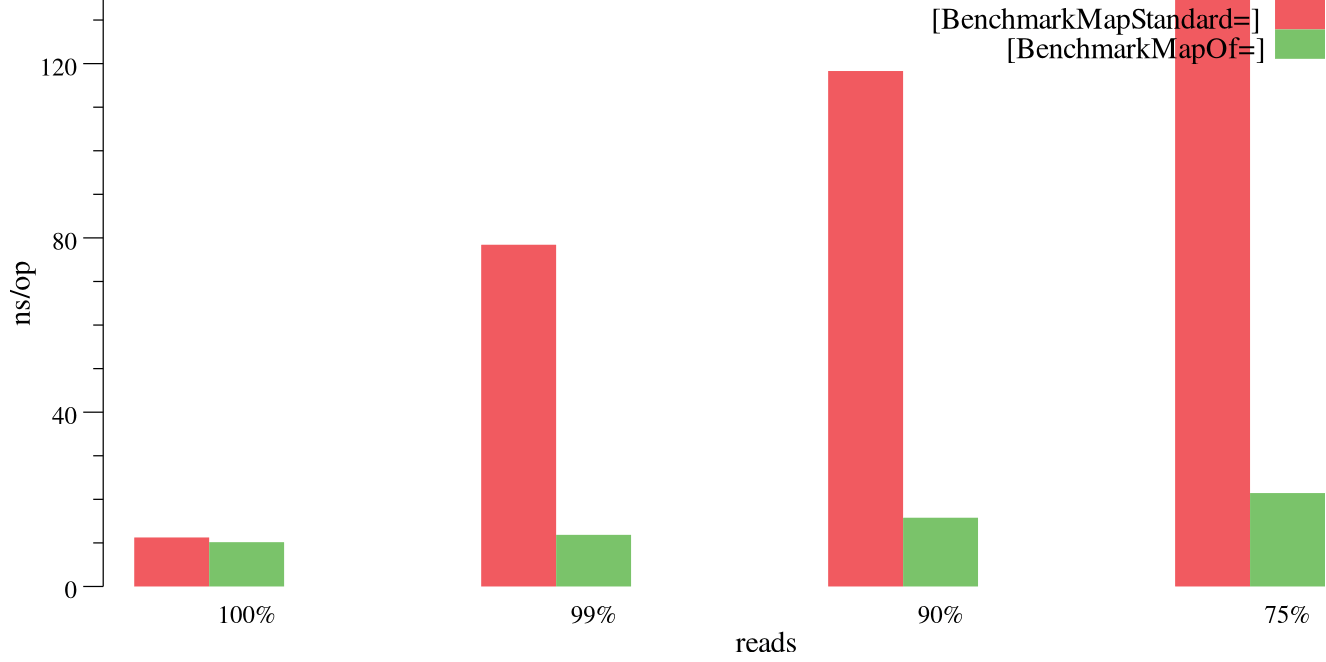
Here, the x axis stands for the percentage of Load operation while the two remaining operations have equal chances to be called, e.g. for the 90% value we have 90% of Load calls, 5% of Stores and 5% of Deletes. The y axis stands for the average time in nanoseconds spend on an operation.
Things get even more interesting with 1M key/value pairs.
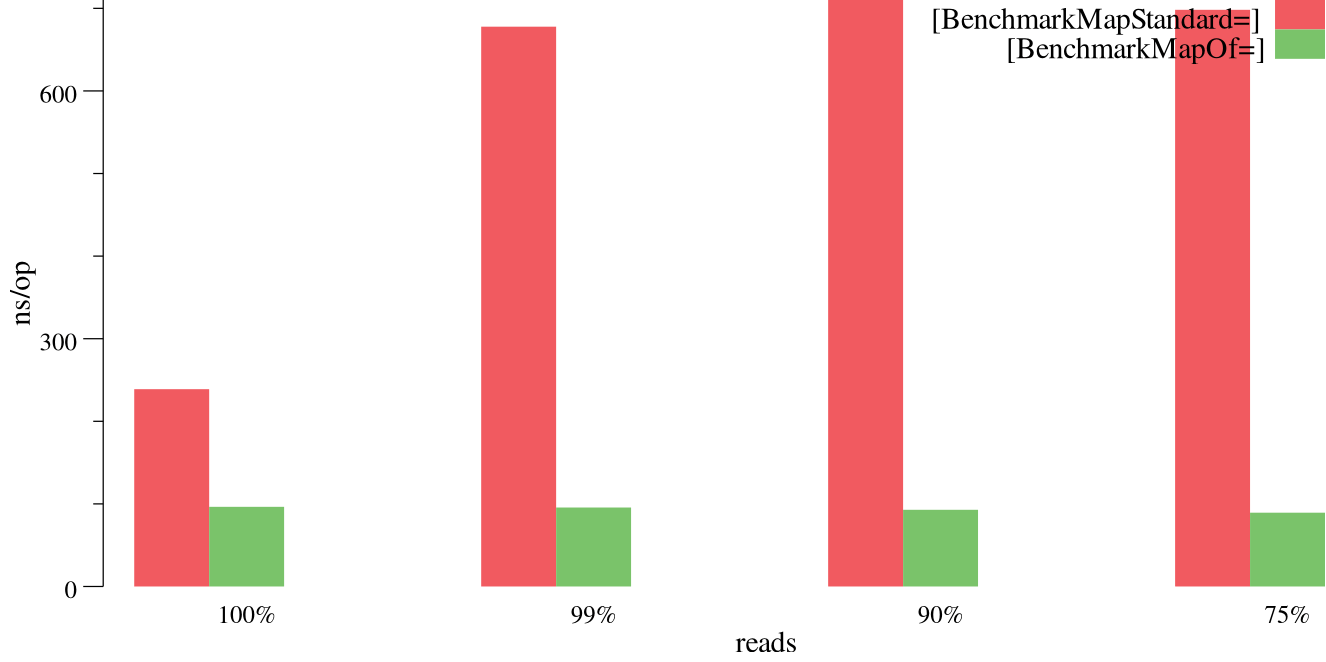
As usual, take the above results with a grain of salt. There might be some scenarios when the standard map is faster, so make sure to test things close to what your application does. Nevertheless, due to the design the standard map is quite limited in terms of scalability in the presence of even a small fraction of concurrent writes. After all, a data structure guarded with a single lock will scale worse than the one with sharded locks. When it comes to reads which are the strongest point of sync.Map, both data structures are on par.
Lessons learned
Hopefully, this post has convinced you to try xsync.MapOf in action and maybe to contribute to xsync. This story is another evidence of the power of open source communities. Without so many contributors, xsync.Map would be still limited in its capabilities. I'm pretty sure that it's not the end of the story and the library would continue evolving in future. Have fun coding and see you next time.




